简介
- 论文名称:《Learning to count objects in images》
- 出处:NIPS 2010
个人收获
- 想通过本文了解问什么采用高斯核计数,但是还是没能理解其中的真谛哎
- 提出了用高斯核生成真值。提出了一种距离计算方法,并将其转化为convex quadratic problem
摘要
文中提出一种新的有监督学习的框架,用于视觉计数任务如显微镜下的细胞计数,监控下的人群计数。我们重点关注训练图片为标记为点的情况。(一个点代表一个实体)
目标是准确计数。论文没有采用监测和标记具体事例的方法。而是把问题转化为评估一个图像的密度图,通过对密度图积分(就是加和)即可得到整张图片的计数。学习推断这样的密度可以被制定为,正则化风险二次损失函数的最小化。文中引入一种新的损失函数来适配这种学习,与此同时可以用通过最大子数组问题(maximum subarray algorithm)的方式求解。然后可以把学习当作凸二次规划可解压缩平面优化。提议的框架非常灵活,因为它可以接受任何领域特定的可视化。一旦训练,我们的系统提供精确的对象计数而且特征提取上的时间开销也很少,使它特别适合需要处理实时数据或需要处理大量可视化数据的应用程序。
#introduction
前面说的跟摘要类似,就是计数选的是人标记一个点,很符合人类的计数习惯并且省力。文中针对这种真值是标点的问题,提出相应的解决办法。并给出一些如何利用除了标点意外的信息。
问题定义:对于给定图片 I,给出一个密度函数F作为一个为途中的每一个像素计算真值的函数。
假设用xp每一个图像中的像素 p 的特征,密度函数可以认为是一个线性变换: xp: F(p) = wT xp. 对于给定的一组训练图片,参数向量 W 通过 the regularized risk framework学习获得, 所以 对训练图片的密度函数估计匹配通过人为标记密度真值(通过在W上的正则化) . (这段话没看懂哦)
相关工作
- 检测,递归两种方法
Framework
真值密度函数可以看成一个基于给定点的 核密度评估。
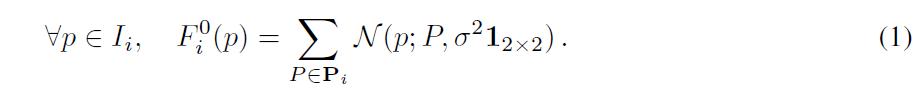
具体的是根据文中标记为1的点,生成相应的高斯核,最后,累计图片中的数字,就是总的计数。文中用matlab 实现,filter 大小是15,方差为4。 一直不太明白这样做的具体意义是什么。特别是filter的大小 该如何选择。(留白吧,希望后面理解了回来补一下)
后面的算法是传统算 就不翻译了。
