简介
- 论文名称:《Dual path multi-scale fusion networks with attention for crowd counting》
- CNN分类
- 基于attention
- 输入数据的分类
- 基于完整图像
个人收获
- 两个相同的网络,一个生成mask,通过attention去除背景,另外一个生成density map,最后两者想乘,得到最后的结果。
解决的问题就是树,灯等背景会被识别成人
观点引入
Problem:
Estimation crowd density map. Existing two major difficult problems: large head scale variations caused by camera perspective and diverse crowd distributions with high background noisy scenes.
Goal:
To further tackle the high background noise issue, we adopt another path of multi-scale feature fusion as attention map path (AMP) with the same structure to learn a probability map that indicates high probability head regions. Then this attention map is used to suppress non-head regions in the last feature maps of DMP, which makes DMP focus on learning the regression task only in high probability head regions. We also introduce a multi-task loss by adding a attention map loss for AMP, which improves the network performance with more explicit supervised signal.(最后一句没看懂,前面的意思是通过一个同样的网络attentionnet来识别出高概率是人头的地图,然后利用这个高概率的人头地图在网络的最后一层去掉那些没有人头的地方的干扰)
思想总结:用att提取出了高概率的人头区域,然后让网络关注人头区域多的位置。多尺度,结合了层次不同但是分辨率相同的feature。
网络结构
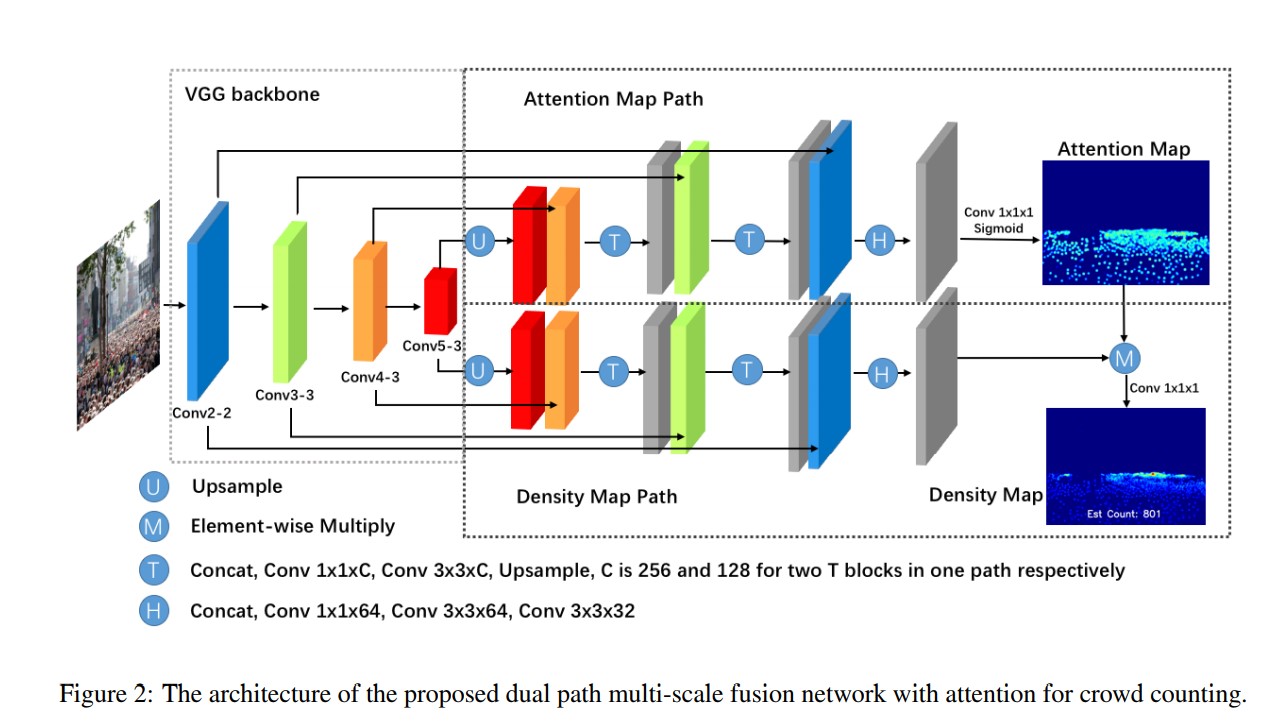
Feature map extractor(FME)
We choose a pre-trained VGG16 with batch normalization as the frond3 end feature map extractor due to its strong feature represent ability and easily to be concatenated by the back-end dual path networks. The first 13 layers from conv1-1 to conv5- 3 are involved to output feature maps with sizes 1/2, 1/4, 1/8 and 1/16 of the original input size. Four source layers, conv2-2, conv3-3, conv4-3 and conv5-3, which represent multi-scale features and multi-level semantic information, will be concatenated by both DMP and AMP
Density map path(DMP)
The DMP of SFANet is constructed in feature pyramid structure as illustrated in Fig.2. Conv5-3 feature maps firstly is upsampled by factor 2, and then concatenate feature maps of conv4-3. The detail of transfer connection block T is shown as Fig.3, which contains concat, conv1×1×256, conv3×3×256 and upsample sub-layers. The second T block has the similar structure concatenating conv3-3 with only different channel size 128, that is concat, conv1×1×128, conv3×3×128 and upsample. Then concatenated outputs of second T block and conv2-2 are feed into header block H with concat, conv1×1×64, conv3×3×64 and conv3×3×32 shown as Fig.3. Every 1 × 1 convolution before the 3 × 3 is used to reduce the computational complexity. Due to previous three upsample layers, we can retrieve the final high resolution feature maps with 1/2 size of the original input. Then element-wise multiple is applied on attention map and the last density feature maps to generate refined density feature maps Fref ine as equation 1: Fref ine = fden ⊗ MAtt (1) where fden is the last density features, MAtt is attention map, ⊗ denotes element-wise multiply. Before this operation, MAtt is expanded as the same channel as fden. At last, we use a simple convolution with kernel 1×1×1 to generate the high-quality density map Mden. Batch normalization is applied after every convolutional layer because we find that batch training and batch normalization can stabilize the training process and accelerate loss convergence. We also apply Relu after every convolutional layer except the last one.
Attention map path(AMP)
The AMP of SFANet has the similar structure with DMP, and output probability map to indicate head probability in each pixel of the density feature map. In this work, we introduce the attention model as follows. Suppose convolutional features output by head block as fatt, the attention map MAtt is generated as: MAtt = Sigmoid(W c fatt + b) (2) where W, b is the 1 × 1 × 1 convolution layer weights and bias, c denotes the convolution operation and Sigmoid denotes the sigmoid activation function. The sigmoid activation function gives out (0, 1) probability scores to make network discriminate head location and background. The visualization of Matt can be seen in Fig.4. The proposed attention map loss will be further discussed the next section.
loss

