简介
##小物体的一些基本常识,摘自知乎
小目标主要还是三个方面存在问题:
- 样本数量:数据本身包含的小目标就少,能跟anchor重叠的更少,造成小目标本身证样本数量低,检测效果差。所以数据还有anchor设置很重要
- 下采样倍率:一般网络速度不能太慢,也就要求下采样倍率不能太低。然而下采样倍数比较高的情况下小目标会因为经过过多次卷积造成过多的信息丢失,导致检测效果差。另一方面,anchor与目标的匹配与下采样倍率直接相关,过低的下采样倍率直接影响小目标与anchor的匹配,造成样本过低,导致检测效果差
- 输入图片尺度:同上,全卷积网络不要求输入尺寸固定,因此多数目标检测框架输入是可以任意的。可是输入尺寸直接影响网络速度,因此输入图片尺度不可以太大,这样同上,小目标信息损失会相对于大目标更大,同时匹配上的证样本更少,导致检测效果更差
##Small Object Detection
小物体检测可以被认为是物体检测的特殊情况,但是一般物体检测器在检测小物体时可能会遇到一些问题,特征表示不足是小物体检测的主要限制。为了克服这个问题,大致有这些处理方法: - 浅层的池化特征用来识别和增强的分类器用来分类
- 对像素进行上采样以获得更精细的表示
- 使用多尺度输入来处理不同尺寸的特征
- 感知生成对抗网络(P-GAN)模型来缩小小对象和大对象之间的表示差异
- 然而,这些方法仍然在无关背景上花费大量计算资源,作者试图从昂贵的卷积运算中尽可能多地排除背景区域。
因为通过短链接的方式和结合底层特征的方式,crowd counting 已经有人用过了,了解一下放大图像的方向。
*主要 论文名称:《CASCADE MASK GENERATION FRAMEWORK FOR FAST SMALL OBJECT DETECTION》
个人收获
- 3个级联的网络,每一个负责,乘以mask后的一个放大倍数后的图片 重点就是mask 找出下一个网络可以放大的地方
观点引入
Problem:
A straightforward solution to solve “small object detection frameworks” is to enlarge the input iamge size.As such, the feature size if proportionally enlarged and the feature representation is finer. howerver, the computational cost is also proportionally increased,and even more of it is wasted on the irrelevant background,making hte entire detection process highly inefficient.(就是找出那些需要放大的小目标,从而提高效率,那么问题的难点或者重点就在于怎么定位小物体和无用的背景区域)
Goal:
they use a low-resolution image estimate a mask that excludes the background regions. then the rest of the regions can be processed at a higher resolution without much cost. they also further adopt a cascade architecture to filter more regions.specifically,the input image is resized into multiple scales,and they are processed in ascending order of scales.For each input scale,a mask is generated for the next scale input in addition to the object proposals.(生成mask,被选中的候选区域会被放大)
benefit:
(1)it significantly reduces the computational cost.
(2)early stages filter easy negatives, so that later stages can focus on hard negative examples.
related work
Object Detection Framework:region-based detectors and
single-shot detectors.
Small Object Detection:
Although small object detection can be considered as a special case of object detection, general object detectors may face some issues when detecting small objects, as Zhang et al. pointed out in [13]. The insufficient
feature representation is the main limitation in small object detection. To overcome this problem, Zhang et al. [13] pool features from shallow layer and adopt a boosted forest classifier. Cai et al. [14] upsample the features to get a finer representation. Hu et al. [15] use multi-scale input to handle faces in different sizes. Li et al. [16] propose a perceptual generative adversarial network (P-GAN) model to narrow the representation difference between small objects and large objects. However, these methods still spend a large amount of computational resources on irrelevant backgrounds.
这几篇还要再去看一下目前就简单粘贴了
#their approach
##Framework Overview
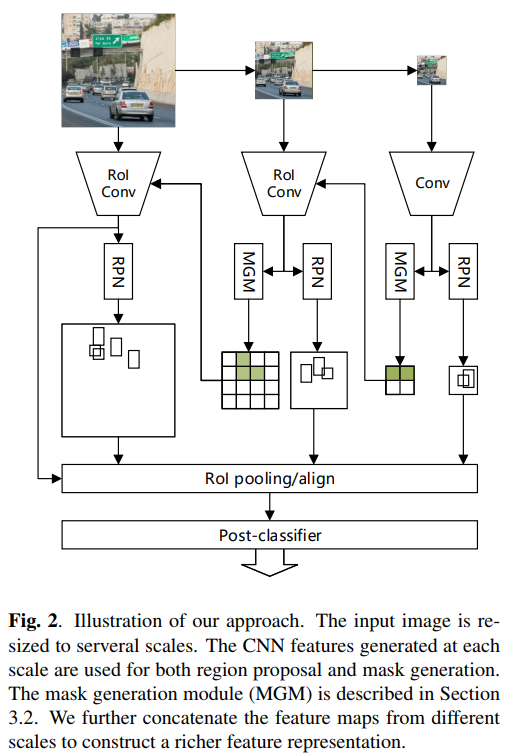
Following the Faster R-CNN [9], we build a region-based detection system with multi-scale input. The input images are resized to several scales. For the smallest scale, we apply a standard RPN [9] to extract the candidate bounding boxes.Meanwhile, the mask for the next scale is estimated by theMGM. The MGM and RPN share the same base convolutional feature maps. Therefore it only introduces little overhead compared to the standard RPN.(mgm 和 rpn 共享 网络,这样可以提升效率,有点像多任务,也想SAFNet,就是真值的区域基本相同,只是形式不同,这时候就可以共用相同的网络结构)
With the mask generated from the previous scale, the
background regions are discarded when an image is fed into
CNNs. For the rest of regions, we use almost the same implementations as the smallest input: standard RPN and MGM.Note that we do not need to estimate the mask for the last input. (小尺寸的生成mask,大尺寸的只计算mask内的东西)
The region proposals are used for post-classification, just like fast R-CNN [8]. We adopt the RoI align method proposed by He et al. [20] to extract regional features from the last convolutional feature maps produced from the largest input. The post-classifier decides which category the candidates belong to. The whole framework is illustrated in Fig. 2.
Mask Generation Module
将图片切割成32*32个patches,当一个patch和真值有交集的时候,它被激活,全部被激活的patch就是MGM.
ground_True坐标映射规则为: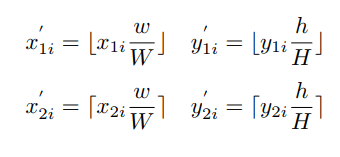
其中,(x1i; y1i)和(x2i; y2i)是第i个box的左上角和右下角的坐标值。没明白为什么要从新映射一下啊直接用坐标算不就行了吗,每懂啊。
采用全卷积网络来生成掩码。它将H x W图像作为输入并生成h x w热图。为简单起见,在骨干网络的最后一个卷积层之后添加池化层以产生具有h x w分辨率的特征映射。然后我们添加两个1x1卷积层。其中一个用于提取掩码生成的特征,另一个用于生成概率图。实际上,MGM的结构与RPN几乎相同。唯一的区别是MGM了解区域是否包含目标,而RPN了解目标的位置。 因为他们的大致区域是一样的只是形式不同而已。 对于MGM,使用Softmax损失函数。由于前景和背景之间的不平衡,使用了所有正例,并随机选择一些负例,使样本比例为1:3。(没理解这里做了什么,就是什么叫随机选取了负例)。 所有示例都在可用区域中选择。这意味着如果某些区域没有被包含在先前的掩码,则在后面训练过程中会忽略它们。
Detection module
The detection module includes two parts: the RPN and the
post-classifier, similar to the Faster R-CNN [9] framework. Since we use multi-scale inputs, the entire network has multiple RPNs and only one post-classifier. For each RPN, we predefine a proper anchor setting, e.g., the low-resolution RPN is expected to detect large objects but ignore small objects. After region proposal, the candidate regions extract features from the feature maps produced by the largest input and feed them into the post-classifier. As some regions are discarded by the MGM, the RPN does not propose bounding boxes outside of the positive regions.
Multi-task Loss Function

